Elastic IPFS is a new type of IPFS peer that runs in the cloud, and what web3.storage uses to make uploads available over the public IPFS network. It’s designed to scale massively, leaning on cloud providers whose infrastructure has been proven to achieve web scale. Their focus and expertise on meeting SLAs as their physical infrastructure grows allows us to rely on them as we also grow. And by allowing users to interact with their data using content identifiers, we function as a layer on top of these cloud providers mitigating their ability to lock you in while providing the same service level.
Some history…
We built a product called NFT.Storage, which turned out to be the first version of the web3.storage platform, in 2 weeks to allow folks at NFTHack to easily onboard data onto the decentralized web. We can, and have, talked at length about the merits of content addressing data and the need to do so in a trustless web.
We also launched web3.storage a few months later as the more general platform for content addressed data (not just NFT-specific). We didn’t quite grasp it at the time, but we were truly bridging the web2 ⇒ web3 gap, by giving developers the familiar APIs to work with and performance and reliability they were used to that enabled them to dip their toes in the cool, cool water of the web3 world, without having to take a giant leap and figure out how to architect and re-architect their applications to work on the decentralized web.
We were amazed and humbled by the popularity of the two products. Right now, they’re approaching 200 million uploads between them, around 500TiB, and around 5 billion blocks!
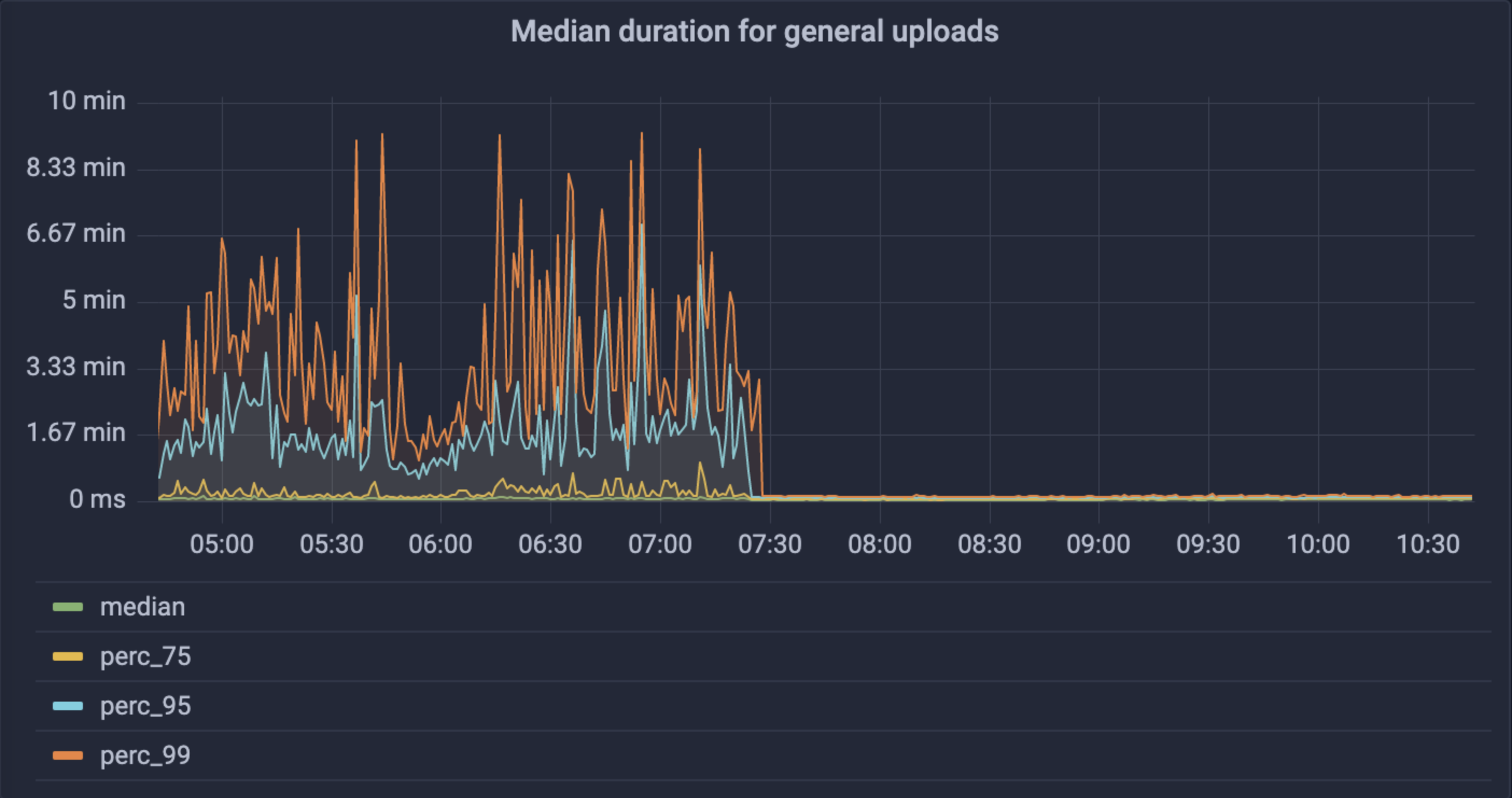
However, it wasn’t a cakewalk to get there. Most notably, the infrastructure we launched with (a giant cluster of Kubo nodes, which is the most common IPFS implementation) wasn’t holding up to the scale we were seeing. As a result, we built and launched Elastic IPFS in July 2022. You can read more about the issues we were seeing and the impact Elastic IPFS made in this NFT.Storage blog post, but to summarize, we saw:
- 99.9% decrease in 5xx errors to uploads
- Mean upload request time from 3-8s to 2-3s
- 99th% upload request time from 1-10 min to less than 10s
The remainder of this post will talk about how web3.storage utilizes Elastic IPFS to run the largest IPFS peer. If you’d rather watch a video, check out Alan’s recent talk at IPFS Camp 2022!
Get it in!
The web3.storage platform accepts CAR file uploads. CAR files are the simplest way to transmit content addressed data to us and afford some favourable characteristics:
- Trustless uploads: You don’t have to trust our service is generating a CID that matches your data because you’re generating it! Simultaneously, anyone who obtains the data can verify they received the exact bytes they asked for.
- Streaming generation: A CAR can be generated from file/application data without having to store a complete representation of the data in memory or on disk (which is great news for BIG uploads).
- Concurrent workflows: Generating the hash of the data before it is fully uploaded allows applications to complete other tasks that use the CID such as storing the hash in a database or on chain while the upload completes.
- Flexibility: There’s no requirement to include a complete graph in your upload, which opens the doors for things like diffs and allows for deduplication savings by referencing data that was already uploaded.
In Elastic IPFS, CAR files are the format of the data at rest, and they are unaltered from the time of receipt. CAR data is stored in buckets provided by cloud services, who are experts in storing data at scale. In combination with distributed compute services, this allow uploads to be accepted at a scale far beyond what a single VM or fleet of VMs could achieve, with zero infrastructure management and entirely automatic scaling.
In comparison to uploading files directly to IPFS or to a cluster of IPFS nodes, there’s no work to do - the recipient doesn’t need to build a DAG - no chunking, hashing, or tree layout happens, the CAR can simply be written directly to the bucket. Elastic IPFS also doesn’t have to do any work advertising blocks to the DHT, which we’ll explain later!
When Elastic IPFS is informed of a new CAR file in a bucket, it asynchronously indexes the blocks it contains. It stores the block CID, its offset in the file and a mapping of which blocks are in which CAR files. This allows Elastic IPFS to serve data directly from buckets using byte range requests.
We currently accept uploads via serverless workers. Users send requests to workers and the workers write to buckets. This works well enough, but unfortunately has limitations such as maximum request size, running time and memory so our new w3up APIs are transitioning towards direct uploads into these buckets via signed URLs to avoid these limitations and also the cost in proxying the content.
Get it out!
Elastic IPFS runs a Kubernetes cluster of “Bitswap peers”. These are specialised IPFS nodes that provide a libp2p Bitswap interface and nothing else.
The Bitswap peers operate over WebSockets to maximise the number of peers that have the ability to connect to them. This even allows peers running in the browser to connect! They are load balanced and they all share the same peer ID. This works out OK, because they all have access to the same dataset. The cluster is setup to scale up and down based on the amount of load that is being experienced.
IPFS fundamentally operates at the block level. It has no knowledge of CAR files other than the ability to import their contents and export a DAG to them. This is where the block index comes in. When an Elastic IPFS Bitswap peer receives a Bitswap message with a list of “wants”, it checks the index to see if it has the block and in which CAR file it can find it. Sending a response boils down to making a range request to a CAR file in a bucket to extract the specific block that is required.
There’s tons of scope here to optimise. There’s 3 main areas we’re working on:
- Spacial locality is taking advantage of the fact that other blocks that make up a DAG are likely to be in the same CAR file. Moreover, they’re likely to be close to each other and not randomly distributed around the CAR. This means that we can reduce the total number of requests we make to extract blocks by specifying a byte range that includes multiple blocks.
- Prefetching refers to intelligently loading a DAG into a cache because the requester probably is going to ask for the rest of the blocks that make up the DAG in the next message(s) they send to us.
- Oversharing refers to actively sending blocks to peers even though they haven’t asked for them. The requester does not know what blocks to ask for next until it receives the blocks it asked for first, however the Bitswap peer does know this (by virtue of reading the blocks that were asked for) so in theory can fill up messages with extra blocks that the client is probably going to ask for next anyway.
Find it!
One of the more difficult aspects of peer-to-peer networking is content discovery. IPFS leans heavily on a DHT for this. In IPFS the DHT maps CIDs to the peers that provide that data. These are called provider records. Provider records are placed by the content provider to peers in the network according to the rules of the DHT. This means that when a peer comes to ask who is providing content it is likely to ask a peer in the network on which the provider record has been placed.
In practice, this means provider records need to be placed for every single block that is stored by a peer and then re-provided periodically so they don’t expire and also to account for network churn.
This quickly became problematic when we were using IPFS Cluster. Our cluster peers had big disks, but they weren’t able to put all the DHT provider records for all the blocks they had before they expired. There was so much work to do that it was also affecting read and write performance. With this knowledge we pivoted to using machines with smaller disks, but more of them. This works out OK but managing a fleet of 50+ Cluster peers comes with it’s own problems, overhead, and costs.
Luckily, we didn’t have to solve this problem. The “store the index” project was created with the aim of indexing ALL of the data on Filecoin and IPFS. As Elastic IPFS indexes the data in CAR files, it also informs the indexer nodes that it is providing those blocks.
Soon, IPFS will be able to discover and use indexer nodes, but until then indexer nodes are hooked up to a set of peers that exist in the network to help boost the DHT. When you ask who is providing a CID, you’re likely to ask one of these peers, and they ask the indexer nodes using the IPFS delegated routing protocol.
Effectively this means that all 5 billion or so blocks that web3.storage and NFT.Storage are discoverable via the DHT (i.e. when you ask the DHT who is providing the content for a given CID), you’ll get the address of Elastic IPFS!
Closing the gap
IPFS has the potential to be the foundation of a better web because it abstracts how a developer, application, or user interacts with data (what we call the “data layer”) from where the data physically sits. As a protocol, it does this via cryptography and peer-to-peer technology. This unlocks more portable, user-centric apps, eliminates broken links, reduces cloud vendor lock-in, improves security, and more.
However, the promise of the protocol can only be fulfilled if it can support great user experiences. This means performance and reliability are table stakes while remaining easy-to-use. This hasn’t always been the case with IPFS, as some of the advantages it provides have also made it more difficult to provide these baseline needs.
In part because of Elastic IPFS, web3.storage is able to provide the speed and dependability that developers need to utilize IPFS while saving them from being exposed to the complexity under the hood. We are excited to continue watching what this enables our users to build!